
RSS to social integration - An example using Lambda, Python, and Amazon Translate
In this article we’ll explore a RSS to social (e.g. LinkedIn) integration using AWS Lambda with Python. We’ll use Amazon Translate to provide the content of the post in Italian for the social platform. The architecture will be defined via Terraform. We’ll proceed as follows:
- Definition of the Lambda infrastructure in Terraform
- How Terraform manages python code
- Python software components
- Production code
- Unit and integration test code
- Integration examples
- Upcoming improvements
Terraform infrastructure
This is the terraform scheme generated with terraform graph command plus some editing on the dot file to add some fancy graphics: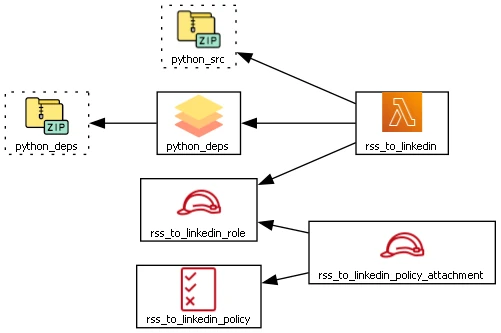
Let’s review the components:
- resource blocks (solid lines)
- rss_to_linkedin main lambda function | main.tf
- python_deps lambda layer | main.tf
- rss_to_linkedin_role role for lambda permissions | iam.tf
- rss_to_linkedin_policy policy for lambda permissions. At the time of writing, only permissions to call Amazon Translate and store logs on Cloudwatch are granted | iam.tf
- rss_to_linkedin_policy_attachment link between role and policy | iam.tf
- data blocks (dashed lines)
- python_src archive file for python source layer | data.tf
- python_deps archive file for python library | data.tf
Python source code in Terraform
Terraform manages python source code in the two archive_file data blocks python_src and python_deps. The first one is dedicated to the source of the lambda function. No particular setup is needed, just having .py files in the folder will do.
1 | data "archive_file" "python_src" { |
The second archive_file is for python dependencies that will be used in the lambda layer
1 | data "archive_file" "python_deps" { |
In this case the libraries that have been installed with pip install for the code to run locally must be installed in the folder python_deps in order to be zipped by the data block. The folder structure under python_deps must respect a peculiar path in order to be used then as a lambda layer. The path is reflected in the pip install command shown here with the target path (-t)
1 | pip install -t python_deps\python\lib\python3.13\site-packages\ requests feedparser beautifulsoup4 boto3 |
Both resources, rss_to_linkedin and lambda_deps, which reference their respective archive_file blocks, have the attribute source_code_hash defined in their blocks. These hashes tell terraform when it’s necessary to rebuild the zip files, that is the python code has changed or the installed libraries have changed.
Python sources
Before describing python sources in details, let’s review a scheme similar to the one in the previous article (An Oauth2 use case - Authenticating and posting articles with images via LinkedIn API (v. 202504)) but focused on components. The actual external calls (linkedin and boto3) have been omitted to favor simplicity
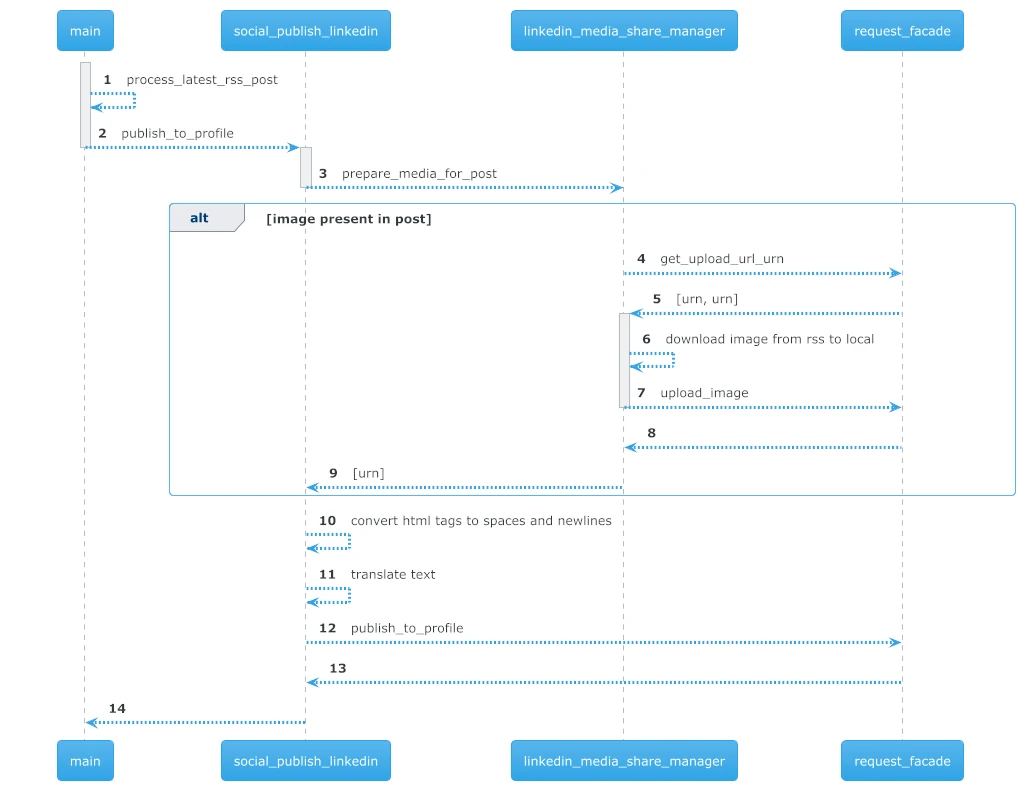
In the following paragraph, we’ll reference the numbers in the image above
Production code
main.py
The main lambda function. (1) It uses the package feedparser to parse the RSS link stored in the environment variable. It could have been also a parameter in the event payload, but this has been for the sake of simplicity. The latest entry from RSS is fetched in the first position of the item array. This is quite brutal, and it’s for sure the next improvement point. Next, the latest_entry object is converted into a result object with the fields that will be used later on. The resulting object starts with empty body and image, and then it scans the content sub-items to populate image and link attributes.
Once the post has been processed, it’s passed to the publish_to_profile function (2).
social_publish_linkedin.py
This component is responsible of prepare the post. It first hides the process of linkin the image to the content from the caller. It calls linkedin_media_share_manager prepare_media_for_post (3) to retrieve (9) the urn (registered by LinkedIn) of the image to be used inside the post.
It then prepares the text by: cleaning html via beautifulsoup4 library; translating it by calling Amazon Translate via boto3 client (10, 11). It then calls request_facade publish_to_profile method to actually post the content (12).
There are two more sub-steps in the cleaning phase that are not depicted in the graph:
- the text must be escaped otherwise LinkedIn will cut off the text at the first special character like parenthesis (see below for the reference).
- The text is placed into a template that adds a preview and a closing for the content such as “This is a new post” and “Continues on…”
Points 13 and 14 are simply the returns to the main caller
linkedin_media_share_manager.py
This component encapsulates the logic used by LinkedIn to use media in the posts. The steps masked by this component are:
- Asking the request_facade for an upload URL and the URN to use for the media via method get_upload_url_urn (4, 5)
- Download the image referenced on the RSS link to the local storage (6)
- Uploading the image payload by calling request_facade upload_image (7, 8)
- Returning its arn to be used in posting the content (9)
Please note that, as depicted in the diagram, if the image is not present in the post the whole “get the url and then upload” is not performed. The publish step will use the link to the post to embed an article in it.
requests_facade.py
This component masks requests body details from upper logic, such as API version changes (e.g. from LinkedIn ugcPost to 202504 api). It uses python requests library to do the http calls. We won’t go in the details of the calls because those have been addressed in the previous post
Libraries used in python
- feedparser - Used for parsing the RSS feed into a json object
- boto3 - Aws client used for connecting with aws translate
- requests - Http client to do get, put, and post requests
- beautifulsoup4 - Used to translate html tags such as headings, line breaks, and paragraphs into newlines
Test code
The code contains a stub (we can call it a mock in its literal sense) of unit and integration tests. This has made easy try the code prior to going live with the lambda otherwise troubleshooting would have been a real pain. A lot of nicer and poshier method would have been available, but those simple calls have done their job.
The command to run the test is (from the root of python source folder)
1 | python -m unittest discover tests |
Four tests are avaiable
- test_remove_html_to_spaces and test_remove_html_preserve_links - these unit tests check that the cleaning of the html is as expected. It has an excerpt taken from the blog html and assert that newlines and spaces are correctly placed.
- test_escape_special_chars - this unit test checks that special characters are correctly escaped
- test_process_event - (commented) this is an integration test that actually calls the main entry point and run all the code util finally post to LinkedIn. It might be over the top, but it offers an instant check on the code against the final result
- test_full_text_conversion this is an integration test that reads the RSS feed and then calls the text conversion (without translation) in order to see what will be the text - only result. Useful for seeing the content as it will be posted on likendin without having to do all the drill
Integration samples
We can download the project on our machine and issue terraform init, terraform plan, and terraform apply to create the lambda. Environment variable can be passed using the syntax --var-file=file. The file should look like this (like the example on GitHub)
1 | rss_url = "your rss to parse" |
Once the lambda is ready in AWS, we can invoke it from the cli:
1 | aws lambda invoke --function-name arn:aws:lambda:us-east-1:2**********8:function:rss_to_linkedin |
and its output will be
1 | { |
What follows are two examples of actual posted content with screenshots and links
Content with link (article)
An example of content with link run against the AWS Blog
with RSS feed located here can be viewed on my Linkedin profile here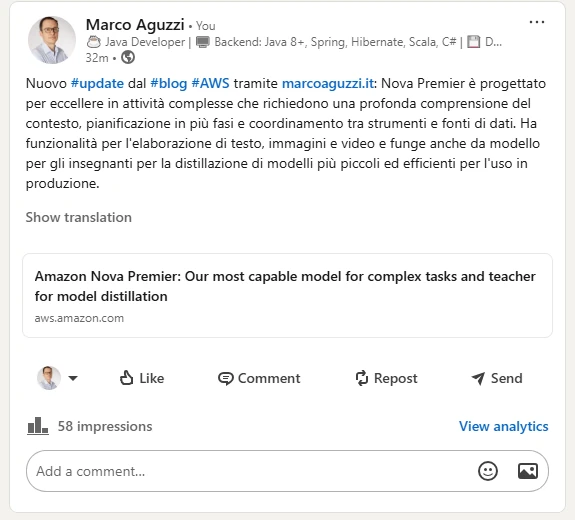
Content with image
An example of content with image run against the marcoaguzzi.it
with RSS feed located here can be viewed on my Linkedin profile here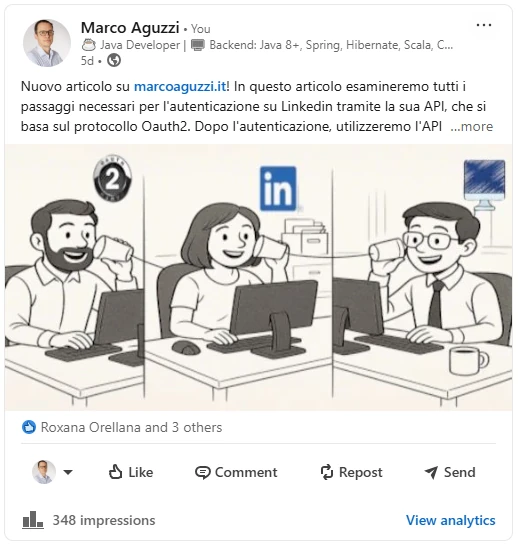
Conclusions
This post has taken the knowledge gained the previous post and encapsulated in an AWS Lambda function. Next steps could be:
- implement a mechanism to know if a post has already been posted on social media with a storage (e.g. DynamoDB)
- schedule the lambda to be called within a certain frequence, like once or twice a day
- better managing the difference between post with image and post with link
- better unit and integration testing with proper mocks
- remove RSS specific parameters from environment variable (otherwise we would have one lambda per RSS)
Thanks for the reading!
Links
- The lambda source code can be viewed on GitHub.
- Reference to the code that prevents special characters to truncate the post: stackoverflow.com/questions/73712703/linkedin-post-api-post-text-gets-cut-off-if-contains
Icon Attributions
RSS to social integration - An example using Lambda, Python, and Amazon Translate




